-
网站加了cdn更慢时缓存规则和域名解析设置应如何调整
2026/3/21 -

通过日志分析与回放提升cdn玩游戏的稳定性与可用性
2026/7/14 -

cdn加速不熟 导致体验差的典型案例与优化复盘方法
2026/5/30 -

海外 cdn 评测如何覆盖安全性与故障恢复能力测试
2026/5/30 -

运维交接与监控策略说明网站cdn如何购买后保障稳定运行
2026/5/30 -

客户案例分享 小麦cdn加速 带来的流量成本降低与转化提升
2026/7/4
技术文档范例 cdn加速写 包含监控与SLA指标的标准模板
一份完整的技术文档模板应至少包含:1)概览与目的;2)系统架构(含CDN加速拓扑、流量路径与缓存策略);3)部署与配置说明;4)监控设计(采集点、采样频率、指标清单);5)SLA/SLI定义与计算方法;6)告警规则与响应流程;7)容量与扩展策略;8)变更管理与回滚方案;9)示例配置与测试用例。以上章节应配套附录(术语、常见故障、接口文档)。在每个章节里,用明确的表格和示例配置来标准化输出。
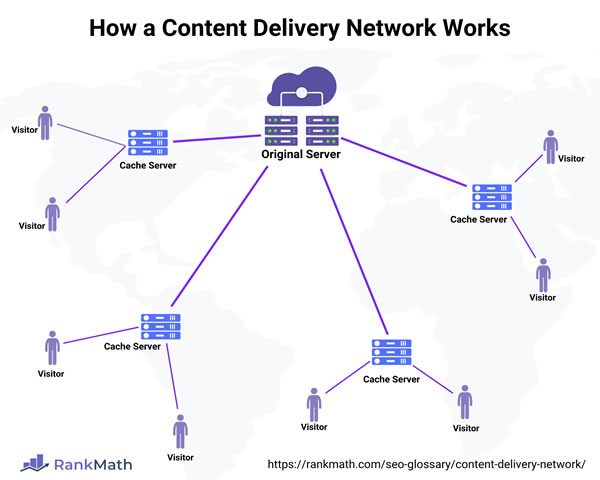
描述时应包含:1)拓扑图(源站、边缘节点、回源路径、负载均衡器);2)路径规则(按域名、路径、Query字符串、Cookie的缓存规则);3)缓存策略(TTL、缓存键、是否忽略缓存、分层缓存);4)静态/动态内容加速策略与回源频率控制;5)证书、跨域与安全配置。建议在文档中用配置片段示例和典型场景(大文件下载、视频点播、API加速)来说明落地细节,并标注对应的测试用例和验证步骤。
关键监控项应包含:1)可用性(HTTP 2xx/5xx 比例、连接成功率);2)性能(95/99分位时延、TTFB、响应体大小);3)缓存效果(命中率、回源率);4)流量(边缘流量、回源流量、峰值并发);5)错误细分(缓存错误、证书错误、DNS故障)。采集点建议覆盖边缘节点、回源、健康检测与客户端侧采样。为支撑SLA指标,需保证采样频率、数据聚合口径一致,明确时间窗口(如按小时/天/30天统计)并保留原始日志以便复核。

SLA应明确SLO/SLI与评估维度:1)可用性SLA(例如99.9%月可用性,计算方式为:可用时间/总考核时间);2)性能SLA(如P99响应时延小于500ms);3)缓存SLA(整体缓存命中率≥85%);4)回源流量阈值与峰值容忍。对每项SLA定义计算公式、数据来源与统计窗口,并列出违约触发条件与补偿方案(例如超出比例按月扣减服务费)。同时定义RTO(恢复时间目标)与RPO(数据丢失容忍),并在文档中给出基于不同故障等级的响应时限与升级路径。
模板应提供可复制的示例:1)CDN缓存与回源的Nginx/云厂商示例配置片段;2)典型Prometheus/Grafana/ELK采集规则与仪表盘示例;3)告警表(指标、阈值、告警级别、通知渠道、需执行动作);4)变更管理流程(变更申请、影响评估、回滚步骤、验证用例)与审批模板;5)故障演练计划与检查表。每个示例应注明适用场景、替换变量与验证步骤,便于工程或运维直接复制到生产环境并快速进行演练与审计。