-

免费云waf日志监控与攻击溯源实用操作方法总结
2026/5/1 -

从网络传输到应用层讲解waf锐速云原理提高防护和响应速度
2026/7/5 -
腾讯云waf状态码升级变更对接入方的影响与兼容性解决方案说明
2026/4/7 -

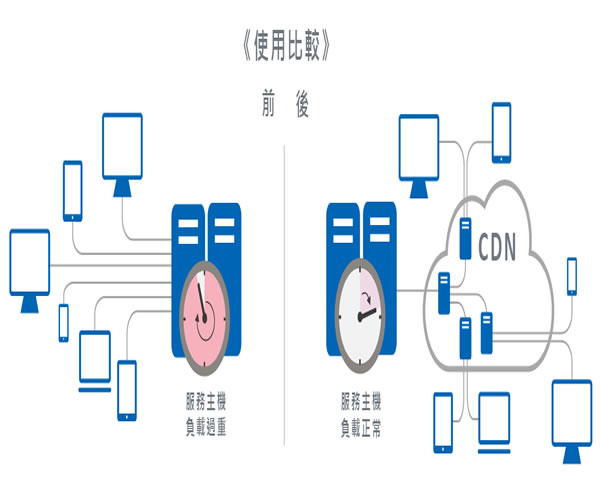
云waf后端是7层负载均衡器与四层设备联动部署最佳实践
2026/4/22 -

面向中小企业的云waf 部署成本控制与性能优化策略
2026/3/12 -

阿里云waf怎么加证书在多域名场景下的证书管理与续期策略
2026/6/5
实战分享萤石云418waf拦截设置对接安全运营中心的流程
本文提供一套面向实战的、可执行的流程,覆盖从策略制定、控制台配置、日志与报警导出,到与安全运营中心(SOC)对接、误报调优和演练的关键步骤,旨在帮助运维或安全工程师快速落地并保持可持续的运维闭环。
哪个模块负责拦截,萤石云418waf包含哪些关键组件?
在平台上,拦截功能通常由核心策略引擎与规则库共同完成。萤石云418waf的关键组件包括:策略管理(Rule Engine)、签名库(Signature DB)、行为分析模块(Behavioral Analysis)、会话/流量代理(Proxy/Ingress)、以及日志/事件导出(Logging/Alerting)。拦截动作由策略管理触发,策略可以是通用签名、正则自定义规则、IP信誉、UA/Referer白名单或速率限制等。理解这些模块有助于后续精细化配置与日志采集点的选择。
如何在控制台设置拦截策略以便对接安全运营中心?
步骤建议如下:1) 先在测试域上启用“检测/告警”模式,逐条评估触发规则;2) 按优先级建立规则组(例如:高级威胁→已知漏洞签名→速率限制→自定义规则);3) 为每条规则设置动作(block/challenge/redirect/log-only)并绑定对应的日志标签(rule_id、severity、attack_type);4) 在策略中开启结构化日志输出(CEF或JSON格式)并配置传输方式(syslog/HTTPS/Thrift);5) 通过API或控制台导出规则列表及变更记录,以便SOC做规则映射与告警关联。关键在于以“可解析、可鉴别”的字段输出拦截事件,便于SOC做后续分析。
哪里可以导出拦截日志,如何保证日志对接后可供SOC高效分析?
常见日志导出点包括syslog、HTTPS/REST回调、消息队列(Kafka)、以及云存储(S3兼容)。推荐做法是:1)优先选择结构化JSON或CEF格式;2)确保字段包含time、src_ip、dst_ip、url、method、rule_id、attack_type、action、resp_code、user_agent、req_headers(关键header)、并在可选项中包含请求体摘要或MD5;3)使用TLS+鉴权(例如API Key或mTLS)保证传输安全;4)在SOC侧建立解析器(Splunk/ELK/QRadar),并在导入时做字段映射与索引策略,保证查询性能。若流量大,考虑采样与分级存储(全部日志归档,拦截事件实时入库)。
为什么要提前设计告警规则,怎么做才能降低误报率并提高告警价值?
告警泛滥会影响SOC效率,因此要从规则级别、关联级别和流程级别进行优化:1)规则级别:给规则分配合理的severity、阈值与窗口期(如1分钟内5次请求判定为攻击);2)关联级别:将WAF事件与IDS/端点、资产标签、业务维护窗口等做关联,只有关联出异常链路时提升告警级别;3)流程级别:设置自动化工单与人工复核流程,对于新规则先走“告警但不阻断”的灰度期;4)误报处理:建立白名单与快速回滚机制,记录误报样本并反馈给规则维护人以进行规则优化。通过闭环反馈和逐步放宽/收紧策略,能够显著降低误报。
多少性能指标和延迟需要关注,在哪里设置以保证SOC实时响应?
针对对接SOC,应关注吞吐、并发连接数、日志传输延迟与丢包率等指标。建议监控项包括:处理延时(ms级)、拦截决策耗时、日志出发到SOC入库的延时(最好<5s即时告警路径)、syslog重试与队列积压、以及CPU/内存与网络链路利用率。配置上:1)为日志传输设置缓冲与批量发送,避免单条网络开销过高;2)在高峰期对采样策略与告警阈值做动态调整;3)设置后端熔断与退避策略,确保当日志通道不可用时不会影响WAF实时拦截能力(优先保证阻断,日志异步归档)。这些指标直接影响SOC的响应时效和研判质量。
怎么进行故障恢复与演练,什么时候需要人工干预?
落地演练和故障恢复是保证长期稳定的关键:1)制定SLA与恢复流程(包含日志通道故障、规则误杀、证书到期等场景);2)定期做“蓝绿切换”或演练流量回放,验证SOC告警链路的完整性与误报处理速度;3)实现自动化回滚(例如规则批量禁用)和快速白名单接口;4)明确人工干预条件:大规模误杀、关键业务中断、日志通道长时间不可用或规则引入未知高风险时触发人工审核。演练后把结果写入Runbook,并把常见问题转换为自动化脚本以缩短响应时间。
