-

企业出海经验谈高防cdn最好的行业在跨境业务中的应用示例
2026/5/29 -
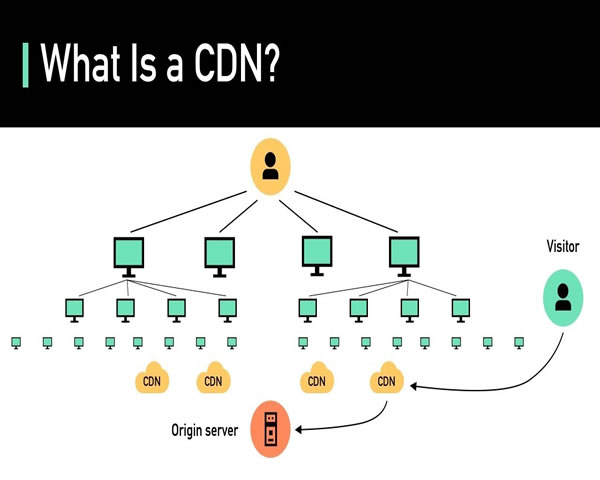
跨国部署考虑因素该选高防ip还是cdn高防节点与带宽权衡
2026/5/28 -

对比分析主流厂商棋牌游戏高防cdn的价格与功能差异
2026/6/19 -

高防cdn香港节点 在突发DDoS攻击下的清洗能力与回源保护实测
2026/5/4 -

节省成本与提升防护高效性高防ip和高防cdn的选择实战建议
2026/3/19 -
DNS层面保护与应用层防护玩高防服务器还是cdn 的选择逻辑
2026/3/6
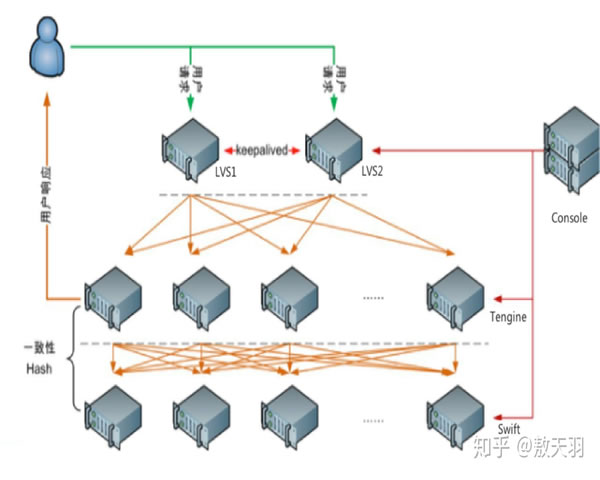
cdn高防项目 在多云架构中进行一致性配置与监控的实施方案
问题一:为什么在CDN高防项目的多云架构中必须做到一致性配置与统一监控?
意义与风险概述
在多云部署下,若没有一致性配置与统一监控,会导致配置漂移、策略不一致和可观测性盲点,进而影响CDN高防项目的抗DDoS能力与业务可用性。跨云差异会造成策略漏配(例如WAF规则、ACL、rate-limit),监控指标割裂(流量、请求延迟与清洗效果无法聚合),最终延长故障定位时间。
关键痛点
痛点包括:云厂商API差异、证书与密钥管理分散、告警噪声与重复告警、配置同步失败导致的安全漏洞,以及流量调度策略不一致引发的清洗误判。
需要达成的目标
目标是通过IaC、GitOps、统一密钥管理与中心化监控,实现“单一源码→多云部署、单一视图→多云告警”的可控运维闭环。
问题二:如何设计一致性配置策略(包括工具与规范)以支持多云CDN高防部署?
设计原则
遵循“声明式、可审计、可回滚、可验证”四原则。使用Terraform或Pulumi做跨云资源的声明式管理,结合Git作为单向真理来源(GitOps),确保配置版本化、代码评审与自动化应用。
工具与模式
推荐采用:1) Terraform + provider 模块化(同时使用remote state与state locking);2) Crossplane 或者 Kubernetes + CRD 作为云资源编排层;3) ArgoCD/Flux 做GitOps下发;4) OPA/Gatekeeper 或 HashiCorp Sentinel 做策略与合规校验。
配置模板与验证
建立统一模块库(CDN、边缘规则、WAF模板、ACL、LB),并通过CI流水线执行lint、plan、静态策略检查和沙箱测试,最后自动化回滚以避免误发布。
问题三:如何实现多云环境下的统一监控与告警(指标、日志、链路追踪)?
架构建议
采用混合观测架构:在每个云侧部署采集层(Prometheus exporters、Fluent Bit/Logstash、OpenTelemetry agents),并通过remote_write或日志聚合通道将数据汇聚到中心化观测平台(如Prometheus Thanos/Cortex、Grafana、ELK/OpenSearch)。
核心要素
必须覆盖:边缘流量指标(QPS、流量峰值、清洗率)、WAF拦截/规则命中、网络丢包与延迟、健康检查与回源失败率。告警通过统一规则引擎推送到PagerDuty/钉钉/企业微信并具备抑制与分级能力。
高可用与多租户策略
使用远程写入+存储侧聚合(Thanos/Cortex),支持跨云查询与历史比对;日志侧用Kafka或对象存储做缓冲,保证短期网络抖动不丢数据;为不同业务或团队设置租户隔离与权限控制。
问题四:在CDN高防项目中,如何将一致性配置与监控具体落地(流量调度、清洗策略、证书与密钥管理)?
流量调度与切换策略
采用DNS GSLB、BGP Anycast 与负载智能调度相结合的方式。使用健康探测+灰度策略实现流量切换,并在切换同时触发配置下发与监控校验,避免切换后清洗策略不同步。
清洗与WAF规则同步
将WAF规则与清洗策略作为配置模块化管理,使用蓝绿/金丝雀发布策略在非高峰期自动下发,结合实时日志(edge日志)验证拦截效果,必要时自动回滚或逐条修正。
证书与密钥统一管理
使用HashiCorp Vault、云KMS或Cert-manager做统一证书与密钥管理,支持动态密钥轮换与审计。将敏感数据从IaC模板中剥离,通过Secret backend注入到运行时环境,保证跨云一致性与合规性。
问题五:如何在运维与安全治理上实现持续合规(审计、自动化修复与演练)?
审计与合规流程
所有变更必须走Git PR流程并触发CI:静态扫描(tfsec/Checkov)、策略校验(OPA),变更审批与自动化执行后记录审计日志。审计数据存入中心日志平台并保留可追溯的变更快照。
自动化修复与响应
基于统一监控触发Runbook执行:常见事件(配置漂移、证书过期、规则误伤)通过自动化脚本或修复Playbook(Ansible/Argo Workflows)快速恢复,必要时通知人工介入并保留回滚点。
演练与SLA保障
定期进行故障演练(包括DDoS演练、跨云故障切换、清洗误判恢复),并用演练结果不断调整门槛和规则。通过SLI/SLO监测清洗成功率、RTO/RPO等SLA指标,形成闭环改进。
