-

cdn又拍云在中小企业中的应用场景与成本测算
2026/3/22 -

合规视角分析最牛的防御cdn对数据隐私和监管的支持力度
2026/6/1 -
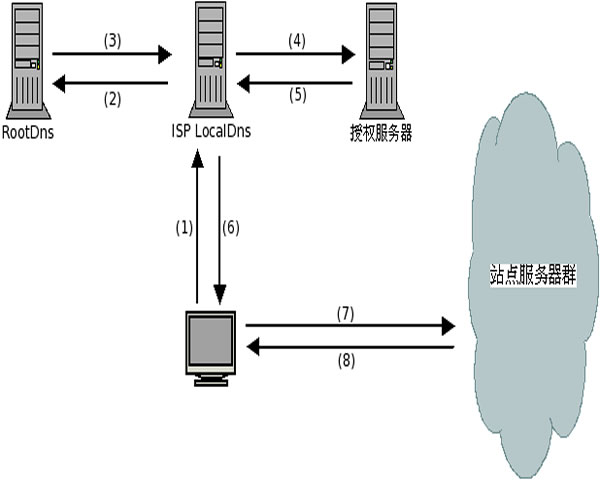
利用数据驱动优化cdn 第一公里路由与链路冗余
2026/4/25 -

动态cdn直播的概念解析与适用场景全面说明
2026/3/18 -

视频站下行流量cdn回源流量在缓存策略调整中的实际案例
2026/4/1 -

cdn项目加盟直播是真的吗如何实地考察服务商与技术团队
2026/4/24
运营优化指南基于融合cdn原理实现流量智能调度
本文在技术与运营层面总结了如何基于融合CDN的原理实现流量智能调度,通过架构设计、调度策略、监控体系和落地步骤,帮助团队提升可用性、降低成本并改善用户体验。文章侧重于可操作的步骤与判断要点,便于在实际环境中快速验证与迭代。
采用融合CDN的核心在于将公有CDN、私有CDN与边缘计算能力进行协同,形成统一的流量服务层,从而实现更灵活的流量分发与性能保障。传统单一CDN在覆盖、成本和控制上存在权衡,通过融合可以在低延时、高可用和成本可控之间找到平衡点。这种模式使得流量智能调度成为可能,通过实时策略调整流量路径,提升整体的交付效率和稳定性。
确定边缘节点数量需基于访问分布、业务峰值和SLA目标。首先进行流量采样与热力图分析,按地区、运营商和时段划分流量密度;其次设定目标指标(如P95响应时间、可用率99.95%);最后通过容量模型估算并留有冗余。一般策略是先以少量节点验证策略(PoC),再按需求逐步扩容,避免一次性投入导致资源浪费。
选择调度策略需结合业务特性:静态内容优先使用基于地理位置和缓存命中率的策略;动态请求可引入基于延迟和实时链路质量的智能路由;流媒体或大文件分发则需要会话保持与带宽感知调度。可以采用多层策略组合:先按地域/运营商做粗粒度路由,再用实时指标进行细粒度切换,以确保稳定性与性能。
关键指标包括响应时延(P50/P95/P99)、缓存命中率、回源流量比例、错误率、会话丢失、成本(带宽与请求费用)以及用户感知指标(启动时间、卡顿次数)。建立统一的监控与告警体系,把这些指标与业务目标(SLA、ROI)关联起来,定期做趋势分析与根因定位,从而指导调度策略的优化。
需要加强的数据采集点包括边缘节点性能、回源链路质量、用户端感知以及第三方网络测量。实现实时感知可通过边缘探针、主动探测(如ICMP/TCP/HTTP打点)和被动监测(日志、流量镜像)相结合。将数据上报至流处理平台,使用时间序列数据库与实时计算引擎为调度决策提供低时延支持。
网络环境和节点状态会发生突发变化,单一策略易导致大面积故障或性能退化。融合策略通过多维度指标决策,同时预设Fallback机制(例如回源降级、切换至备用CDN、限流降级)能保证核心服务连续性。容错设计要考虑检测灵敏度、切换频率控制与回切保护,避免“抖动”带来的二次故障。

将算法落地需要建立调度面板、策略下发接口和回滚机制。建议采用分层控制:调度引擎在控制层做决策,边缘执行层负责快速响应;调度规则以可配置的策略库形式管理,支持灰度发布与A/B测试。运维与研发协同通过CI/CD与SRE实践,将策略变更纳入版本管理和回滚流程,保证可观测性与可追溯性。
优先推进的场景包括用户分布广、延迟敏感、带宽/费用占比高或存在合规要求的业务。风险评估要覆盖性能风险、成本风险和合规风险:通过模拟流量、压力测试和小范围灰度验证来量化影响,设置熔断和告警门槛,并准备回滚计划与应急通讯链路。
成本与效能的权衡应从带宽成本、缓存命中率、节点运维成本与用户体验四个维度做平衡。重点关注的是“单位用户体验成本”,即用最小的花费换取最大的体验提升。通过智能调度,将冷门流量引导到低成本路径,把热点内容留在高命中率的边缘节点,以实现总体成本最优化。
持续优化需要构建闭环:设定KPI→实施策略→A/B/灰度测试→监控评估→根据反馈迭代。引入自动化实验平台和回滚保障,定期进行容量规划与策略回顾。通过机器学习辅助预测流量峰值并预置资源,可以提前缓解突发压力,实现真正的流量智能调度与长期的运营优化。
在实践中,结合业务场景选择合适的技术栈与合作伙伴,先做小范围验证再逐步推广,能够以较低风险实现性能与成本的双重提升。以上要点可作为实施路线图的参考,帮助技术与运营团队快速搭建并迭代基于融合CDN的智能流量调度体系。