-
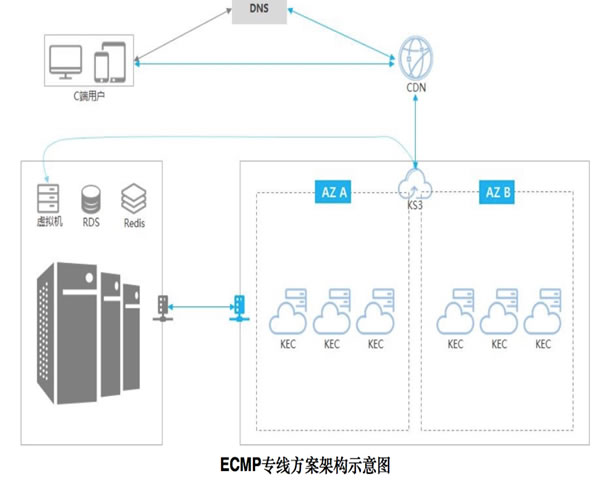
cdn游戏应用 在移动端与端游场景下的落地实践总结
2026/5/15 -
从SEO与安全角度分析为什么要确认哪个网站配置cdn 了及其影响
2026/6/26 -

cdn企业网站安全防护能力评估与应急响应实践手册
2026/5/23 -

从零开始搭建博客 使用海外cdn加速奶爸建站 成本与性能平衡
2026/3/20 -
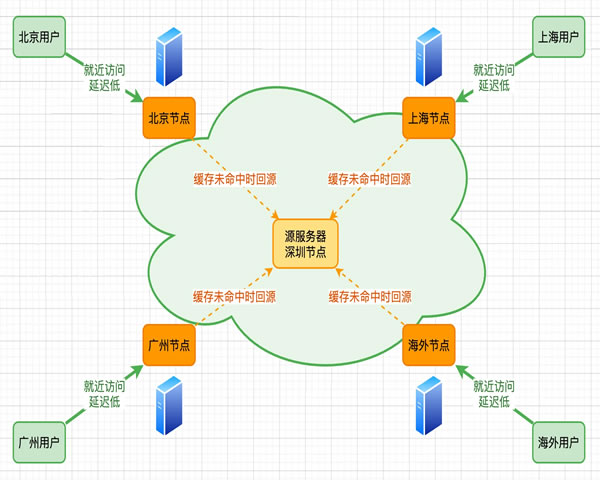
CDN安全加速构建于自动化运维提升响应速度的实施步骤
2026/4/6 -

迅游游戏加速器初始化cdn失败初始化时日志分析与处理建议
2026/6/8
游戏更新上线后出现游戏读取cdn失败的最佳回滚实践
1. 为什么会出现游戏读取cdn失败,如何快速判断是否需要回滚?
首先判断故障范围与原因:查看监控(错误率、响应时延)、玩家上报与日志,区分是单点CDN节点故障、配置错误、还是发布包本身引入的问题。若推出新版本后短时间内错误率飙升且能复现,且无短期热修方案,则应考虑回滚以保障玩家体验。快速判断原则是“影响面、重现性、修复时间窗口”——影响面大、可稳定重现且预计修复时间超过SLA恢复目标时优先回滚。
快速判断步骤
1)确认错误码与cdn返回;2)对比回滚前后流量和错误率;3)检查配置/资源路径是否被修改;4)评估热修可行性与风险。如果热修风险或耗时高于回滚成本,执行回滚。
需要优先关注的监控指标
错误率、请求失败率、资源加载时延、CDN节点可用性、回源流量骤增等,均可提示游戏读取cdn失败的根因方向。
关键提示
准备好回滚脚本和回滚权限,避免在判断不清时盲目反复发布。
2. 回滚前需要准备哪些关键步骤以降低二次故障风险?
回滚前要确保回滚包、回滚流程和回退环境验证完备。准备包含:可用的稳定版本包、回滚脚本/自动化流水线、回滚检查清单、监控回归预案和通信计划。并提前冻结新发布相关配置变更,确保回滚不被后续自动化进程覆盖。
回滚核对清单
1)确认稳定版本哈希;2)验证配置兼容性(如cdn路径、缓存策略);3)备份当前状态与日志;4)通知相关团队与渠道公告计划。
并发回滚与数据一致性
若更新涉及后端数据迁移,回滚需评估数据回滚策略,避免数据库不一致导致新旧逻辑冲突。
通信要求
回滚前通知客服、运维与产品,以便统一口径并减少玩家误解。
3. 技术上有哪些常见且可靠的最佳回滚实践可以立即采用?
常见实践包括蓝绿部署、金丝雀发布与快速切换DNS/CDN版本。蓝绿允许瞬时切换到旧环境;金丝雀能先在小流量验证回滚目标;CDN层面可回退到旧资源版本或修改路由策略降低影响。
实践清单
1)使用版本化资源路径,便于CDN回滚;2)保持静态资源的历史副本;3)在CI/CD中保留回滚按钮并自动执行回退脚本;4)在CDN控制台快速切换回源或回退缓存。
自动化回滚脚本要点
脚本需包含回滚前备份、依赖检查、降级步骤与回滚后验证(健康检查、样本流量测试)。
演练频率
定期演练回滚流程(至少季度),确保团队熟悉操作并发现边界条件。
4. 回滚后如何验证服务已恢复并防止问题再次发生?
回滚完成后立即执行健康检查:合成监控请求、真实用户监控(RUM)与关键路径压测,观察错误率与体验指标回归至正常水平。同时核对CDN缓存状态与回源流量,确保旧资源已被正确恢复并生效。
验证步骤
1)对比回滚前后关键指标;2)在多个地区抽样测试资源加载;3)让客服验证玩家反馈;4)观察24小时波动确认稳定性。
防止复发
回滚后应进行根因分析(RCA),修复发布流程、增加预发布验证、强化CDN回退能力与自动化监控告警。
记录与改进
将回滚过程、时间点、影响范围与决策日志记录在案,用于优化发布与回滚SOP。
5. 如果回滚不可行,有哪些替代方案能快速缓解游戏读取cdn失败?
当回滚不可行时,可采用以下措施:临时调整CDN配置(切换回源、节点黑名单/白名单、下线问题节点)、启用应急静态资源托管(备用域名/备份CDN)、使用客户端降级逻辑(回退到本地缓存或简化资源请求)。这些措施可以在不回滚代码的情况下快速恢复大部分玩家体验。
应急措施优先级
1)CDN配置快速回退;2)启用备份资源域名;3)下发轻量级客户端热修补;4)临时开放降级接口以减少依赖。
风险与注意事项
应急措施可能带来数据一致性或性能开销,需评估成本并设定回收窗口。确保所有变更有可逆步骤。
演练与文档
为这些替代方案建立可执行的SOP并在非高峰时段演练,确保在真实事故中能快速落地。
